
I’m having a perfectly good day until all of a sudden I see in my Wazuh Dashboard that new alerts have abruptly ceased to arrive. I confirm that:
- The wazuh-manager services are all running with plenty of connected agents.
- The alerts.json files on my managers are growing normally.
- Filebeat is running on all Wazuh managers.
- All wazuh-indexer services are up and the Wazuh indexer cluster is in a green state.
- The indexers have plenty of disk space to spare.
What could possibly be wrong? Welcome to the reality of shard management in your Wazuh indexer cluster! Shards are by necessity a limited resource, and running out of them has halted my Wazuh indexing more often than service failures or inadequate free disk space. In this blog I will walk you through the significance of index shards, confirming if you have maxed them out, and what to do about it if you have — both on the shorter and longer term.
What are Wazuh index shards?
If configured to do so, Wazuh indexer at index creation time will split indexes into multiple primary shards and attempt to provision them on separate indexer nodes for optimal performance. However, if only one indexer node is available, multiple shards for a new index can all end up on the same node, with no benefit at all. Furthermore, Wazuh indexer can also be configured to allocate one or more replica shards duplicating each primary shard on separate indexer nodes for data resiliency. Shards have a purpose, but they are a limited resource, and can add up quickly. For example, if your wazuh-alerts-* indexes are being rotated daily (the default), with three primary shards per index plus one replica shard, then every day your indexer cluster will allocate at least six new shards. Unless at a similar rate you are removing old indexes manually or via ILM policy, you may use up the maximum number of shards that each of your indexer nodes is capable of managing, possibly well before you reach your data retention goals, even though you have copious free disk space.
Have you run out of shards?
Your Wazuh indexer cluster has a default and sensible limit of 1000 shards per data node indexer. Once an indexer reaches its shard limit, it will not create any new indexes until shards are freed up or the limit is increased by configuration or by adding one or more additional indexers to the cluster.
In Wazuh Dashboard, navigate to ☰ ➜ Indexer management -> Dev Tools and execute this API command to see where things stand on your Wazuh indexer cluster:
GET /_cluster/healthThe output will have this basic appearance. This example represents a single node indexer cluster that has reached its shard limit of 1000:
{
"cluster_name": "wazuh-indexer-cluster",
"status": "green",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"discovered_master": true,
"discovered_cluster_manager": true,
"active_primary_shards": 1000,
"active_shards": 1000,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}Here we see that the active_shards value (1000) is equal to the number_of_data_nodes value (1) times 1000, meaning the shard limit has been reached and new index creation will not take place until this is resolved.
Is your Wazuh SIEM wasting shards?
Especially in the case of Wazuh all-in-one installs, or any other case in which the Wazuh indexer cluster consists of only one indexer, it is common for users to find that they have been using three times the needed number of shards since they first started. This is because Wazuh’s Installation guide does not address the fact that Wazuh’s default index template is configured to assign three primary shards to every new wazuh-alerts-* index, which needs to be tuned in light of the actual node count of the Wazuh indexer cluster.
Check if existing wazuh-alerts-* indexes are split into too many shards.
Navigate to ☰ ➜ Indexer management -> Index Management -> Indexes.
Enter “wazuh-alerts” into the Search field.
Look at the Primaries and Replicas columns.
If you only have one Wazuh indexer, then you should see only one primary shard and zero replica shards configured for each wazuh-alerts-* index, like this:
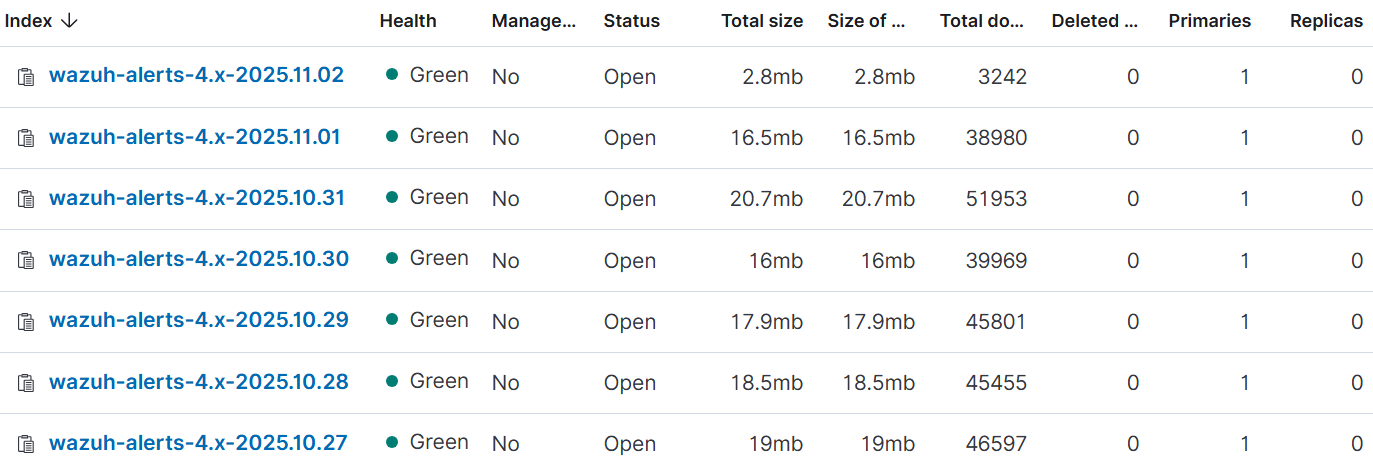
In the above instance, more than 1 primary shard per index is wasting shards.
If you have a Wazuh indexer cluster with two or more data nodes, then the primary shard count per index should not exceed the number of data nodes. While a plurality of primary shards per index is beneficial for performance, you may or may not be able to afford to split up every wazuh-alerts-* index to have a separate shard on every single data node. Balance the benefit of improved performance against your projected need for shards when your cluster has fully reached your data retention target. Do the math and budget accordingly.
Remediating too many shards per index
Prevent creation of future indexes with too many shards
Especially in the case of Wazuh all-in-one installs, or any other case in which the Wazuh indexer cluster consists of only one indexer, it is common for users to find that they have been using three times the needed number of shards since they first started. In Wazuh’s User manual, the Wazuh indexer tuning document does indeed address how to adjust Wazuh’s default index template to assign an appropriate number of shards to new wazuh-alerts-* indexes. However, in Wazuh’s Installation guide, I find no reference to the shard count issue or the tuning document, meaning people are prone to miss addressing this issue until they experience unnecessary shard exhaustion.
Do make sure that you are using the version of Wazuh documentation that corresponds to the version of Wazuh you are using. You may need to click on the version dropdown in the upper right corner of the documentation page and pivot to the version that applies to you. This will impact the steps you will be instructed to take.
After making this adjustment to the Wazuh template, newer indexes will be created with a smaller count of primary shards. As the older indexes with excessive primary shards are gradually removed, your Wazuh indexer cluster’s shard capacity to accommodate more concurrently open indexes will gradually increase.
Get some breathing room by raising the per-indexer shard limit
While tuning the template is a good first step, it is not retroactive, so initially your maxed out shard use will still be at 100% of your configured capacity. Manually deleting older indexes is a common way to free up shards, but if that is not an option in your case, then a temporary increase of your Wazuh indexer cluster’s total_shards_per_node setting may be called for. It is generally best not to increase this greatly, nor to keep this limit permanently raised, as there can be negative performance implications of doing so. Still, it would most likely be harmless to raise it to 1200 for a time.
To do so, navigate to ☰ ➜ Indexer management -> Dev Tools, and execute the following API call:
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.total_shards_per_node": "1200"
}
}Plan to put it back to the default as soon as you no longer need this limit raised, with this API call:
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.total_shards_per_node": null
}
}Retroactively change the primary shard count of existing indexes
If after tuning the Wazuh template for a smaller number of shards per index, you need to promptly and dramatically reduce your overall shard utilization without adding new indexers, then you must re-index past indexes. This will apply the settings of your newly tuned Wazuh template to the past indexes as they are being re-indexed.
Note that re-indexing is an intensive operation that can take hours or days to complete, and can exert substantial load on your Wazuh indexer cluster, depending on the number and size of the indexes involved. The re-indexing process is lightly touched on in the Wazuh documentation here. Some time ago, I authored a powerful script to manage and optimize the process of reindexing large numbers of indexes, which I successfully used to reindex the Wazuh indexes of most of my clients. I plan to present this tool to the community in my blog slated for publication in mid November.
A commonly unanticipated side-effect of re-indexing is that the re-indexed replacements of old indexes will have an immutable creation_date attribute assigned to them that reflects when the re-indexing took place, not when the original index was created. This throws off Wazuh lifecycle management age-based index retention policies, because such policies calculate index age based on the creation_date attribute. The result is that re-indexed old indexes will not be deleted when you expect according to your Wazuh lifecycle management policy, because they appear to have been created at the time that they were actually just re-indexed. My workaround for this issue is to use the OpenSearch fork of the Elasticsearch Curator tool to handle my age-based index retention policies in place of Wazuh’s built-in Index lifecycle management facility. Curator is able to calculate the age of indexes based on the datecode suffix in their names. I have a blog article on this topic slated for publication in mid-late November.
Options when the shard count per index is reasonable, but you’ve still run out
What if your wazuh-alerts-* indexes already have only one shard each but your total shards are still maxed out? Depending on the specifics of your situation, you have several possible options.
Manually delete old indexes
You could delete older indexes that you no longer need to retain, to free up their shards. The effect is nearly immediate.
For example, to delete all the January 2025 wazuh-alerts-* indexes, navigate to ☰ ➜ Indexer management -> Dev Tools and execute this API call:
DELETE /wazuh-alerts-4.x-2025.01.*Be careful with index deletion. There is no “undo” option.
Establish or revise an ILM data retention policy to automatically delete old indexes
You could also create your first Wazuh Index lifecycle management policy to delete older indexes, or adjust your existing policy to delete older indexes more aggressively. Note that in either case, you must also retroactively apply the new/revised policy to your existing indexes or they will not be affected. Even then, you may wish initially to manually delete current indexes that the policy would classify as slated for deletion, to free up those shards immediately.
Add one or more additional Wazuh data node indexers
You may need to scale your Wazuh indexer cluster horizontally with deployment of one or more additional data nodes. These could be on separate physical servers, VMs, cloud instances, or containers. What I specifically recommend against is trying to run parallel Wazuh indexer services on the same OS instance. It is possible, but as someone who has done it before, I say “Save yourself the headache and just don’t go there.” I found that approach to be both fussy and fragile.
Apply a wider rollover period to the wazuh-alerts-* index name pattern
If you can afford to maintain unique wazuh-alerts-* indexes on a per-month or per-week basis, instead of a daily basis, this can dramatically reduce your cluster’s shard requirements. As an alternative to the default daily rollover of wazuh-alerts-* indexes, in which they are suffixed with a YYYY.MM.DD datecode, consider switching to a weekly (YYYY.WW) or monthly (YYYY.MM) rollover period if your index shard sizes permit. It is recommended by OpenSearch here that you seek to have your shard sizes below 30-50 GB to keep your indexer cluster healthy and performant. Assess what your current average wazuh-alerts-* daily index shard size is, and see what multiplying it by 7 would bring it to for a weekly rollover shard size or by 30 for a monthly rollover shard size. Some of my smaller clients produce a low enough daily alert volume that I rotate their Wazuh alerts indexes monthly, which achieves a 30-to-1 reduction in their shard consumption.
To start writing all new wazuh-alerts-* indexes using a weekly or monthly index name pattern instead of the default daily name pattern, follow this procedure:
On your standalone or master Wazuh node manager, make a backup copy of the your wazuh-alerts-* pipeline.json file
sudo cp -pr /usr/share/filebeat/module/wazuh/archives/ingest/pipeline.json /usr/share/filebeat/module/wazuh/archives/ingest/pipeline.json-backupEdit the /usr/share/filebeat/module/wazuh/archives/ingest/pipeline.json and find this section that controls the generation of specific wazuh-alerts-* index names.
{
"date_index_name": {
"field": "timestamp",
"date_rounding": "d",
"index_name_prefix": "{{fields.index_prefix}}",
"index_name_format": "yyyy.MM.dd",
"ignore_failure": false
},Completely replace that section with this for weekly rollover:
{
"date_index_name" : {
"description" : "weekly rotation of wazuh-alerts-*",
"field" : "timestamp",
"date_rounding" : "w",
"index_name_prefix" : "{{fields.index_prefix}}",
"index_name_format" : "yyyy.ww",
"ignore_failure" : false
}
},or with this for monthly rollover
{
"date_index_name" : {
"description" : "monthly rotation of wazuh-alerts-*",
"field" : "timestamp",
"date_rounding" : "M",
"index_name_prefix" : "{{fields.index_prefix}}",
"index_name_format" : "yyyy.MM",
"ignore_failure" : false
}
},Save and exit the pipeline.json file, and then make Filebeat push the changed pipeline definition to the Wazuh Indexer cluster, where it will take effect immediately, though not retroactively.
sudo filebeat setup --pipelinesIf for any reason you want to put the pipeline back to the way it was, just do this
sudo cp -pr /usr/share/filebeat/module/wazuh/archives/ingest/pipeline.json-backup /usr/share/filebeat/module/wazuh/archives/ingest/pipeline.json
sudo filebeat setup --pipelinesThanks for reading!
I hope that you found this article helpful. Gradually learning the above information in the “school of hard knocks” took me quite a bit of time, and my hope is that this blog will save you plenty of the same — both time and knocks. As always, you are welcome to comment on this blog with general questions or to inquire of me by email about possible direct private assistance related to this or other Wazuh issues.